Slide
Show JP
☰
探索
サインイン
サインアップ
アップロード
×
ダウンロード
カテゴリーなし
FIT2006イベント企画講演資料
Document
31 号
シュトルム・ウント・ドランクッ
行動不能 毒 散漫 肥満 呪い 睡眠 愚か
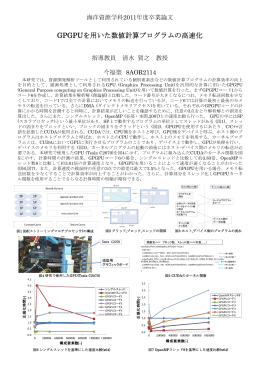
GPGPUを用いた数値計算プログラムの高速化
「銀河鉄道の夜」
方二語彙の個人性と社会性 - 広島大学 学術情報リポジトリ
コンピュータの中身
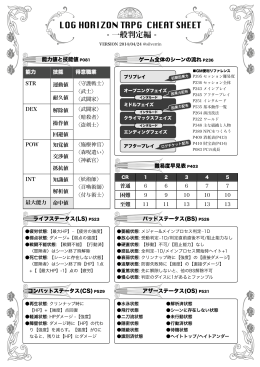
LOG HORIZON TRPG CHEAT SHEET
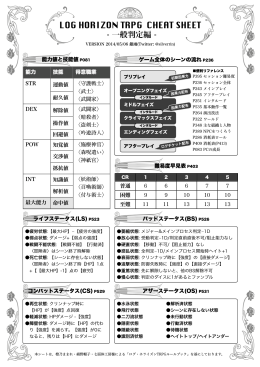
ログ・ホライズンTRPG 補助シート
演劇における「自然」
シュトゥルム・ウント・ドラング期に至る シェイクスピアの受容