Slide
Show JP
☰
探り
ログイン
ユーザーアカウントの作成
Upload
×
ダウンロード
No category
「わかりやすいパターン認識」 第1章:パターン認識とは pp.1~12
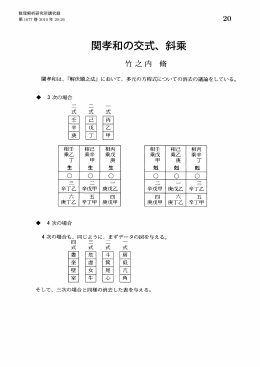
関孝和の交式、斜乘
いかなる辺展開でも正多面体は重なりを持たない (計算機科学と
数学月間活動から見た教育数学
Title 算額における測量術とその教材化 - Kyoto University Research