Slide
Show JP
☰
探索
サインイン
サインアップ
アップロード
×
ダウンロード
カテゴリーなし
付属資料 WG2成果レポート
つくば市体育協会の傘下にあるレッドドラゴンフライの抱える
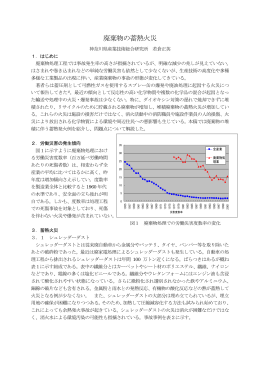
廃棄物の蓄熱火災 - プラスチックリサイクル化学研究会
DB検索 演習問題
議会報告会報告書
今は昔・積み重ねた経験の重さ(上) 森本洋
福山リサイクル発電施設 - 日本環境衛生施設工業会
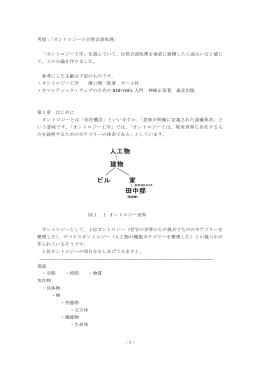
-1- 考察: オントロジーと自然言語処理」 「 「オントロジー工学」を読んで
ビッグデータ活用 保有データのオープンデータ(LOD)化を実現
コミックデータ内関係抽出のためのデータフォーマットの提案