Slide
Show JP
☰
探り
ログイン
ユーザーアカウントの作成
Upload
×
ダウンロード
No category
グラフィカル・ガウシアン・モデル
非接触ワーク搬送ツール「KUMADE」 『吸っていません吹いてます、触っ
プレゼンテーションのスキルvol2
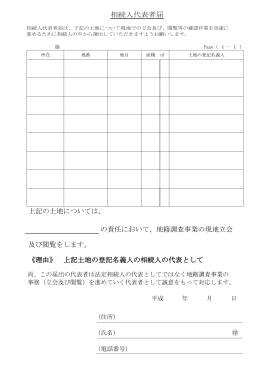
03地籍 相続人代表者届