Slide
Show JP
☰
探索
サインイン
サインアップ
アップロード
×
ダウンロード
カテゴリーなし
10/01(月
経済統計学 第二回 Business Statistics
経済統計 第一回
09/27(木)
経済統計 第一回
Document
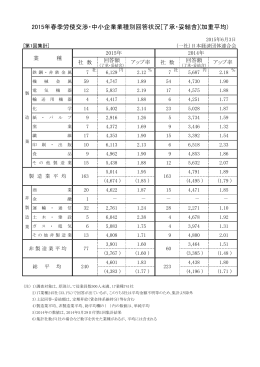
2015年春季労使交渉・中小企業業種別回答状況
標準化変量(PDF)