Slide
Show JP
☰
探索
サインイン
サインアップ
アップロード
×
ダウンロード
カテゴリーなし
コレスポンデンス分析と因子分析によるイメージの測定法
【クロッキー幸せを運ぶの巻】 配達途中に子供たちの嬉々とした声に 遭遇
競艇選手の成績に関する統計的方法
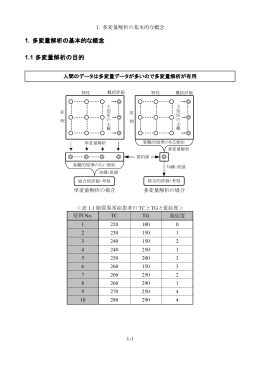
1.1 多変量解析の目的
99 回薬剤師国家試験 問 194 多変量解析の各手法のうち、量的変数を
目次 1.テキストマイニングとは 2.TEXTORVA について 3.TEXTORVA
都市と郊外における女子大生の ファッションに対する意識の
関心抽出に基づく話題構築支援に関する研究
Document