Slide
Show JP
☰
探索
サインイン
サインアップ
アップロード
×
ダウンロード
カテゴリーなし
共有メモリ
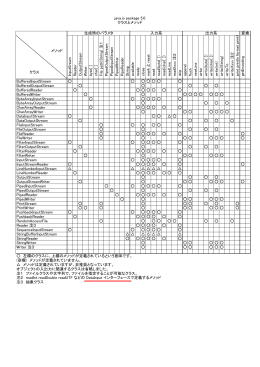
java.io package 5.0 クラスとメソッド 生成時のパラメタ 入力系 出力系
第11回 組み込み関数・文関数 1.組込み関数 数式の中で三角関数や
ppt
トランザクション管理機構
情報処理 (第12回) (2012/6/11・茂木) 1 先週の解答例 2 バブルソート
ppt - C-SODA
2 data文
ppt file
ppt file
ハードウェア・ソフトウェア協調設計技術
こちら - 株式会社グロスディー
情報処理 (第7回) (2011/5/23・茂木) 1 先週の演習の解答例