Slide
Show JP
☰
探索
サインイン
サインアップ
アップロード
×
ダウンロード
カテゴリーなし
知識に基づく探索
+ h(n)
講義ノート
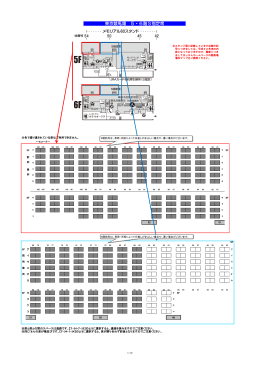
東京競馬場 5・6階S指定席