Slide
Show JP
☰
探索
サインイン
サインアップ
アップロード
×
ダウンロード
カテゴリーなし
情報知能学基礎演習 豊田秀樹(2008)『データマイニング入門』 (東京図書
(2008)『データマイニング入門』 (東京図書)第6章
6年問題
チンパンジー ゴリラ オランウータン
e120. GAINウェブサイトの紹介:類人猿に関する情報収集
校長室だより
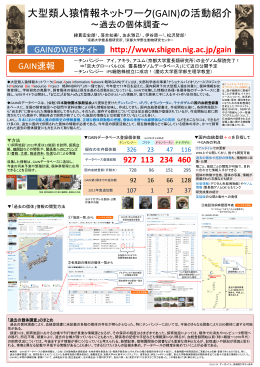
大型類人猿情報ネットワーク(GAIN)の 10年の活動を振り返っ
飼育下チンパンジーおよびゴリラにおける性格評価と糞便中
「たくいつ!」前半戦
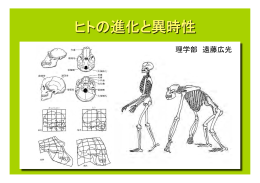
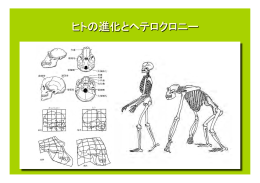
ヒトの進化と異時性
2013heterochrony05_Homo01.
多変量解析ゼミ 第10回