Slide
Show JP
☰
探索
サインイン
サインアップ
アップロード
×
ダウンロード
カテゴリーなし
pptx - 東京大学
ねこ将棋
参考資料 (21KB)
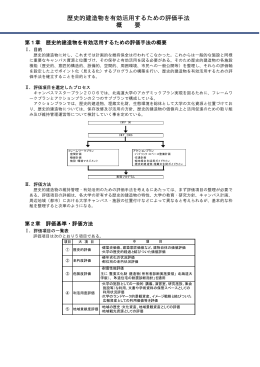
歴史的建造物を有効活用するための評価手法 概 要
企業が求める人材(宮崎)
34 - 電子情報通信学会
評価表現辞書を用いた評判情報の極性値計算 Calculation of Polarity
モンテカルロ木探索 並列化、囲碁、マリオAI
PDFファイル - kaigi.org
presentation - 松田研究室
pptx - 東京大学
シミュレーション論Ⅰ
モンテカルロ法を用いたボードゲームの対戦プログラム : 双対グラフ上の